
ANNIS
ANNIS is an open source, cross-platform (Linux, Mac, Windows), browser-based search and visualization architecture for complex multi-layer linguistic corpora with diverse types of annotation.
ANNIS, which stands for ANNotation of Information Structure, was originally designed to provide access to the data of the SFB 632 - “Information Structure: The Linguistic Means for Structuring Utterances, Sentences and Texts”. It has since extended to be used by a large number of projects annotating a variety of phenomena. Since complex linguistic phenomena, such as information structure, interact on many levels, ANNIS addresses the need to concurrently annotate, query and visualize data from varied areas such as syntax, semantics, morphology, prosody, referentiality, lexis and more. For projects working with spoken language, support for audio / video annotations is also provided.
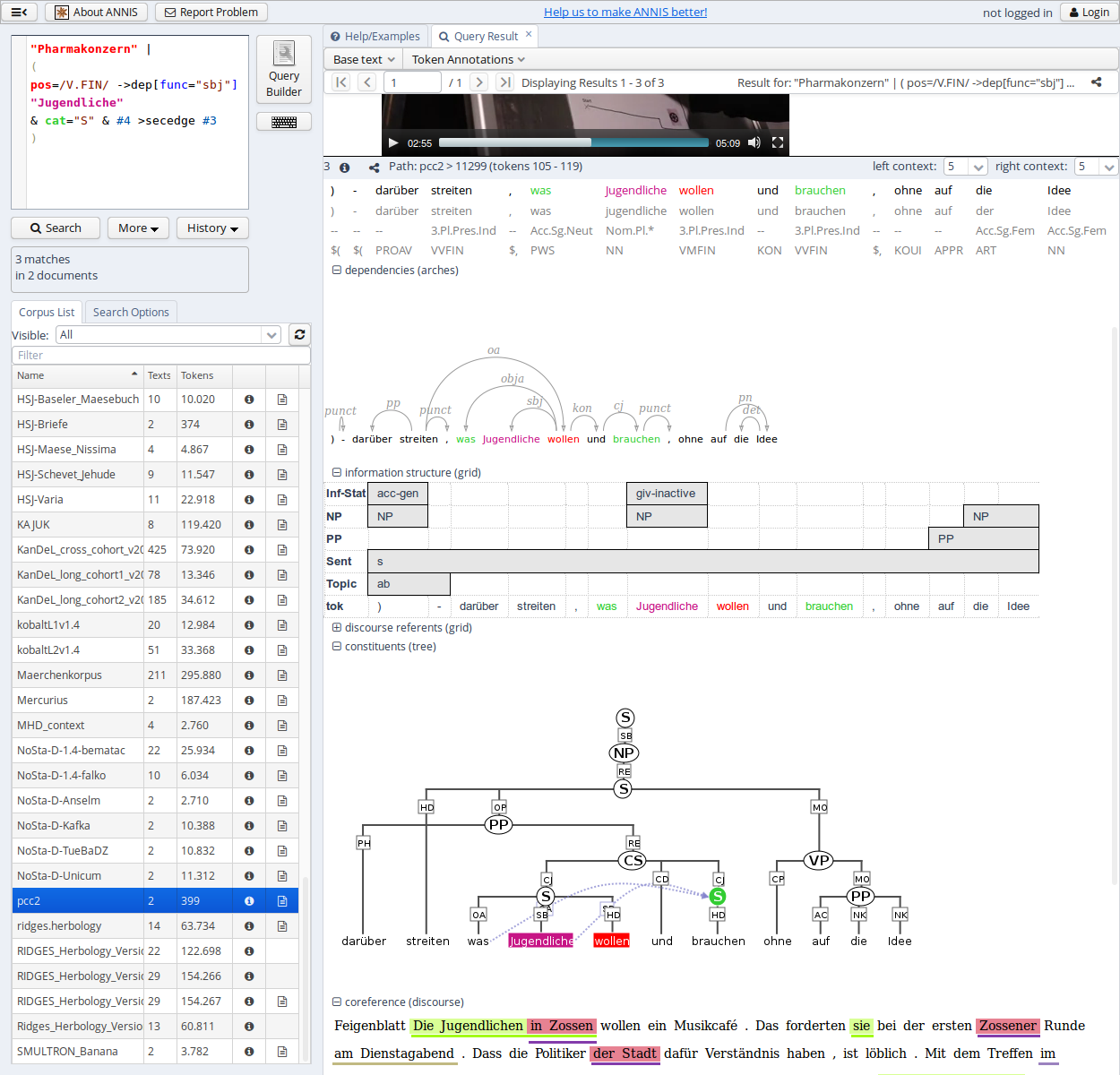
ANNIS user interface